
머신러닝으로 기본적인 데이터 분석과 예측을 배워 왔다면, 이제는 딥러닝을 통해 더 복잡한 문제를 다룰 수 있습니다. 딥러닝은 인공신경망을 여러 층으로 쌓아, 이미지나 문장처럼 구조가 복잡한 데이터를 스스로 이해하게 만드는 기술입니다. 대표적인 딥러닝 모델들을 하나씩 살펴보며, 각 모델이 어떤 문제를 해결할 수 있는지를 구체적으로 알아보겠습니다.
✅ LeNet-5 – 패션 상품 이미지처럼 단순한 시각 데이터 분류
딥러닝의 시작점이라 할 수 있는 LeNet-5는 이미지 인식 문제를 해결하기 위해 만들어졌습니다. 합성곱 신경망(CNN)의 기본 구조를 가지고 있으며, 합성곱층과 풀링층을 통해 이미지에서 중요한 특징을 추출합니다.
모델의 입력으로는 흑백 이미지가 들어가며, 합성곱 연산을 통해 이미지의 윤곽, 모서리, 질감 같은 패턴이 탐지됩니다. 이후 풀링 연산으로 특징의 크기를 줄여 계산 효율을 높이고, 마지막 밀집층에서 각 클래스로 분류합니다.
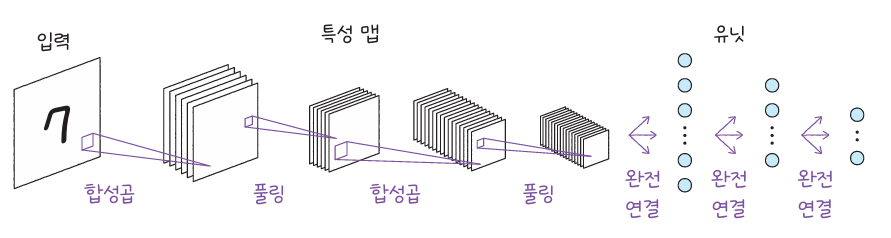
LeNet-5는 두 개의 합성곱층과 세 개의 밀집층으로 구성됩니다. 합성곱층에서는 필터가 이미지의 작은 영역을 훑으며 특징을 찾아내고, 풀링층에서는 중요하지 않은 정보를 줄여 모델이 핵심적인 패턴만 학습하게 만듭니다. 활성화 함수로는 시그모이드나 렐루(ReLU)가 사용되며, 비선형성을 부여해 모델이 복잡한 패턴을 표현할 수 있도록 합니다.
케라스로 구현한 LeNet-5는 패션 MNIST 데이터셋에서 옷, 신발, 가방 등 10가지 범주의 이미지를 분류할 수 있습니다. 이 모델을 통해 합성곱층, 패딩, 스트라이드, 풀링의 개념을 익히고 CNN의 작동 원리를 시각적으로 이해할 수 있습니다. 단순한 구조이지만 CNN의 기초를 체계적으로 학습하기에 적합합니다.

✅ VGGNet·ResNet – 복잡한 이미지에서 세밀한 패턴 구분

VGGNet과 ResNet은 이미지넷 대회에서 큰 성과를 거둔 대표적인 CNN 모델입니다. VGG는 동일한 크기의 필터를 여러 층 반복해 쌓은 단순한 구조로, 설계가 명확하고 이해하기 쉽습니다. 각 층이 점차 더 복잡한 특징을 추출해 가며, 입력 이미지의 시각적 세부 정보를 정교하게 분류합니다.
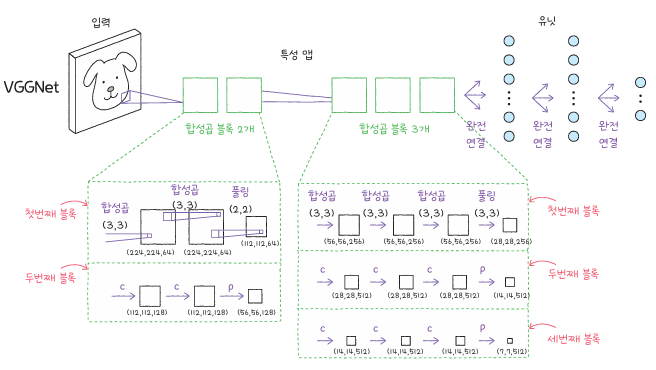
VGGNet의 가장 큰 특징은 3×3 크기의 합성곱 필터를 연속적으로 사용하는 점입니다. 이 방식은 계산량을 크게 늘리지 않으면서 더 깊은 네트워크를 구성할 수 있게 해 줍니다. 케라스의 keras.applications 모듈을 사용하면 VGG16, VGG19 모델을 불러와 바로 사용할 수 있으며, 이미지넷 데이터셋에서 사전 훈련된 가중치를 함께 제공합니다.
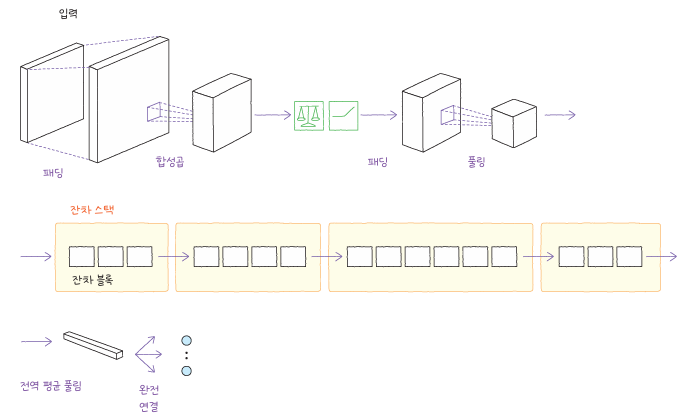
ResNet은 신경망이 깊어질수록 학습이 어려워지는 문제를 해결하기 위해 잔차 연결(skip connection)을 도입했습니다. 이 연결은 이전 층의 출력을 그대로 다음 층으로 더해 줌으로써 정보 손실을 줄입니다. 이 구조를 통해 훨씬 더 깊은 신경망도 안정적으로 학습할 수 있으며, 학습 속도와 정확도를 모두 개선했습니다.
ResNet의 잔차 블록에는 배치 정규화(batch normalization) 함께 적용됩니다. 이 정규화는 학습 과정에서 각 층의 분포를 일정하게 유지시켜, 훈련이 안정적으로 진행되도록 돕습니다. 케라스에서는 ResNet50, ResNet101 등의 사전 훈련 모델을 불러와 이미지 분류에 활용할 수 있습니다.
VGG와 ResNet을 실습하며 CNN이 단순히 이미지를 분류하는 도구가 아니라, 계층적 구조를 통해 데이터의 의미를 점점 추상화하는 메커니즘이라는 점을 자연스럽게 이해할 수 있습니다.
✅ DenseNet·MobileNet·EfficientNet – 빠르고 효율적인 이미지 분류
딥러닝 모델이 발전하면서 성능이 높아지는 동시에 계산량과 파라미터 수도 빠르게 증가했습니다. 이 문제를 해결하기 위해 등장한 것이 DenseNet, MobileNet, EfficientNet입니다.
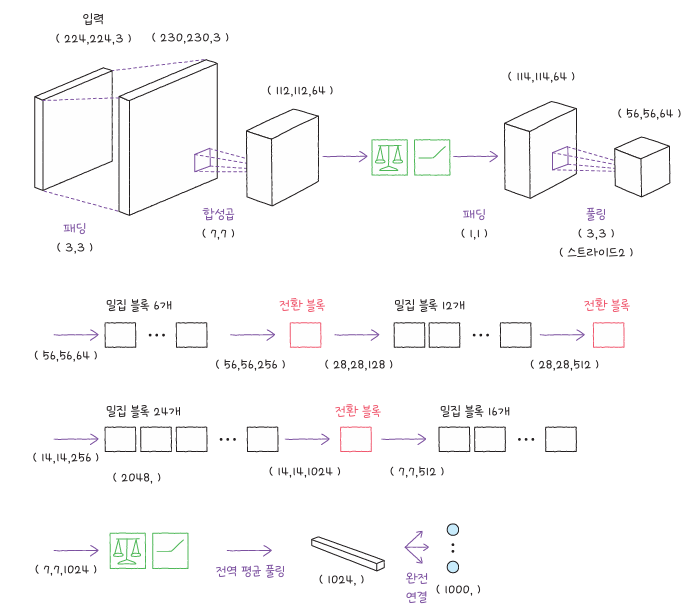
DenseNet은 각 층의 출력을 이후 모든 층과 연결하는 밀집 연결(dense connection) 구조를 사용합니다.이로써 정보가 여러 층을 거치며 손실되지 않고 전달되어, 더 효율적인 학습이 가능합니다. ResNet의 잔차 연결보다 연결의 범위가 넓기 때문에, 작은 모델에서도 높은 정확도를 기대할 수 있습니다.
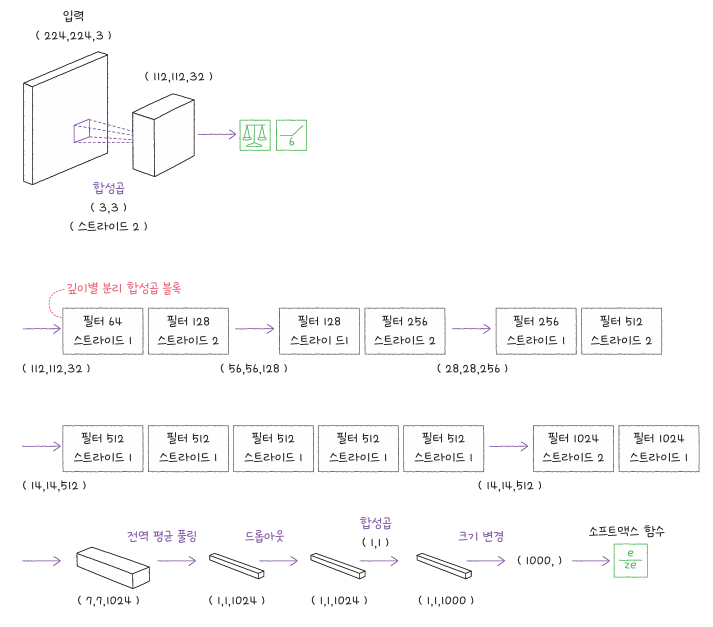
MobileNet은 계산 효율을 극대화한 모델입니다. 합성곱 연산을 일반적인 방식 대신, 깊이별 합성곱(depthwise separable convolution)으로 나누어 수행합니다. 이 방식을 통해 파라미터 수를 크게 줄이면서도 비슷한 수준의 정확도를 달성할 수 있습니다. 덕분에 스마트폰이나 임베디드 환경에서도 실시간으로 이미지 인식이 가능합니다.
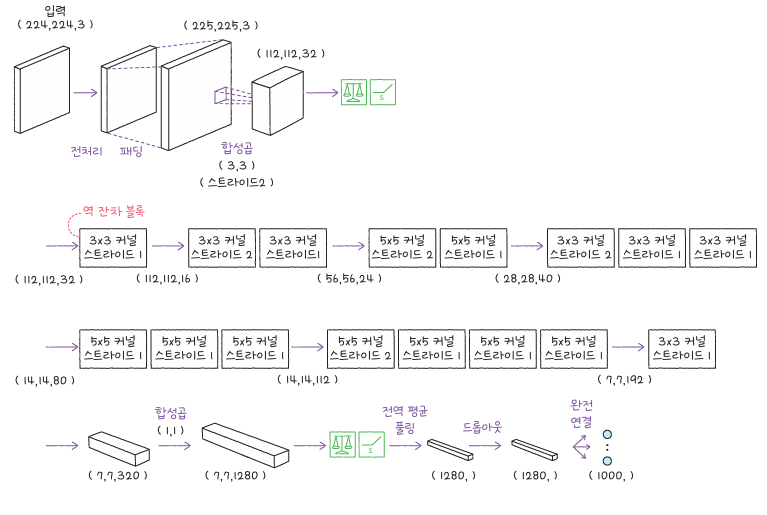
EfficientNet은 MobileNetV2의 아이디어를 확장해, 층의 수, 채널의 수, 입력 해상도를 일정한 비율로 조정하는 복합 스케일링(compound scaling) 방식을 사용합니다. 이 덕분에 모델 크기(EfficientNetB0~B7)를 유연하게 선택할 수 있으며, 작은 모델에서도 뛰어난 효율과 성능을 보여 줍니다.
이러한 모델들은 텐서플로 허브와 허깅페이스에서 사전 훈련된 형태로 제공되어, 이미지 분류, 물체 탐지, 품질 검사 등 다양한 응용 작업에 바로 사용할 수 있습니다. DenseNet과 EfficientNet을 비교하며 정확도와 효율의 균형을 설계하는 방법을 익힐 수 있습니다.
✅ BERT – 문장 속 단어의 의미를 파악해 감정 분류
BERT는 텍스트의 문맥을 이해하는 데 특화된 트랜스포머 인코더 기반 모델입니다. 문장에서 단어가 사용된 위치와 주변 단어를 동시에 고려하여, 단어의 의미를 정확하게 파악합니다.
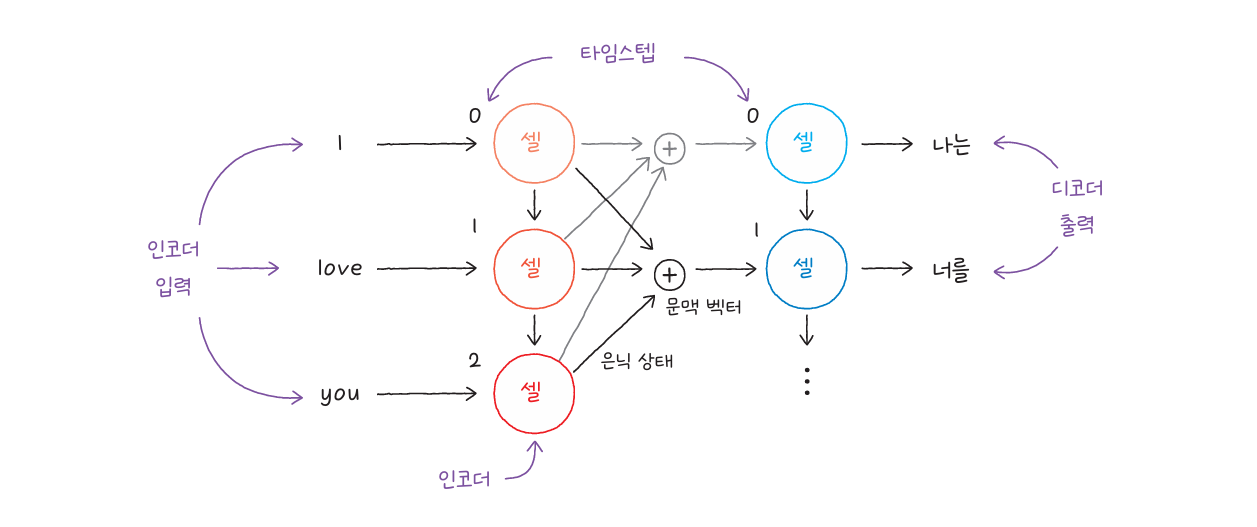
입력 문장은 토큰 단위로 분리된 후 임베딩 과정을 거쳐 모델에 전달됩니다. 여기에 단어의 순서를 반영하기 위해 위치 임베딩이 추가됩니다. 이후 여러 개의 셀프 어텐션(Self-Attention) 층을 통과하며 문맥 정보를 학습합니다.
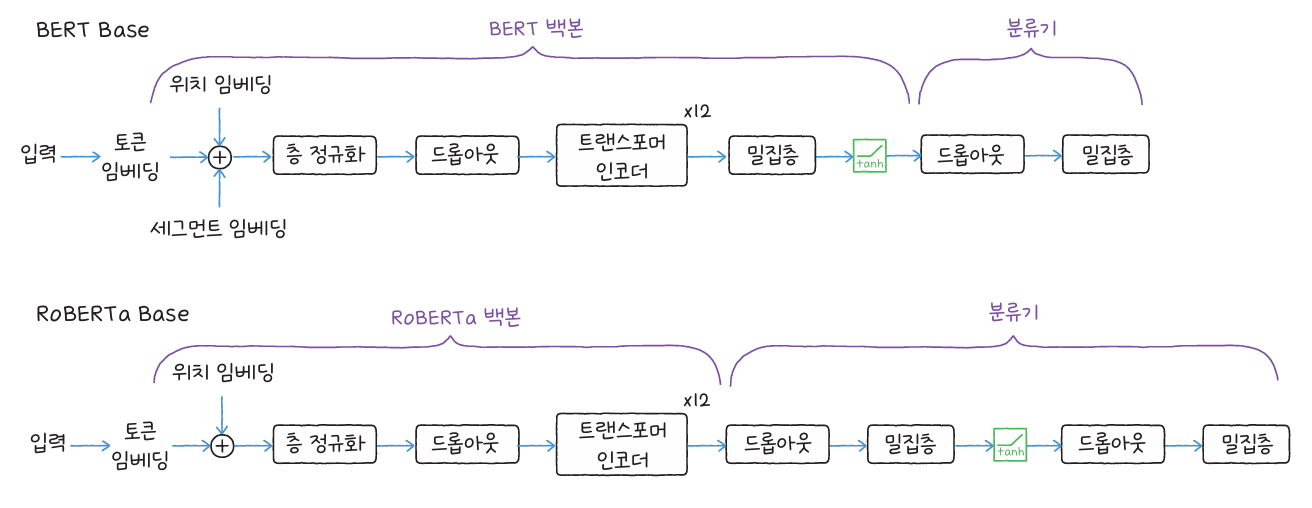
BERT는 감정 분석, 질문 응답, 문장 분류, 개체명 인식 등 다양한 자연어 처리 작업에 활용됩니다. 케라스NLP의 BertClassifier 클래스를 사용하면 클래스 개수에 맞게 마지막 층이 자동 구성되어, IMDB 영화 리뷰와 같은 감정 분석 데이터를 손쉽게 다룰 수 있습니다.
후속 모델 RoBERTa는 훈련 데이터 규모를 확장해 정확도를 높였고, DistilBERT는 지식 정제(Knowledge Distillation) 기법으로 BERT의 크기를 절반으로 줄였습니다. 두 모델 모두 허깅페이스 transformers 라이브러리에서 바로 불러와 사용할 수 있습니다.
BERT를 실습하며 트랜스포머의 핵심 구조인 어텐션 메커니즘이 어떻게 문장 전체의 관계를 학습하는지 이해하게 됩니다.
✅ GPT-2·Llama·Gemma – 주어진 문장을 이어 쓰는 생성형 언어 모델
GPT-2는 트랜스포머의 디코더 구조를 기반으로 하는 대표적인 텍스트 생성 모델입니다. 입력된 문장의 다음 단어를 예측하며, 한 단어씩 이어 붙여 자연스러운 문장을 생성합니다.

훈련 과정에서는 미래 단어를 보지 못하도록 마스크드 멀티 헤드 어텐션을 사용합니다. 이로써 모델은 이전 단어의 정보만 참고하여 다음 단어를 예측합니다. 케라스NLP나 허깅페이스 transformers 라이브러리를 통해 GPT-2 모델을 불러와, top-k, top-p, 빔 서치 등의 샘플링 방식을 사용해 다양한 문장 생성을 실험할 수 있습니다.
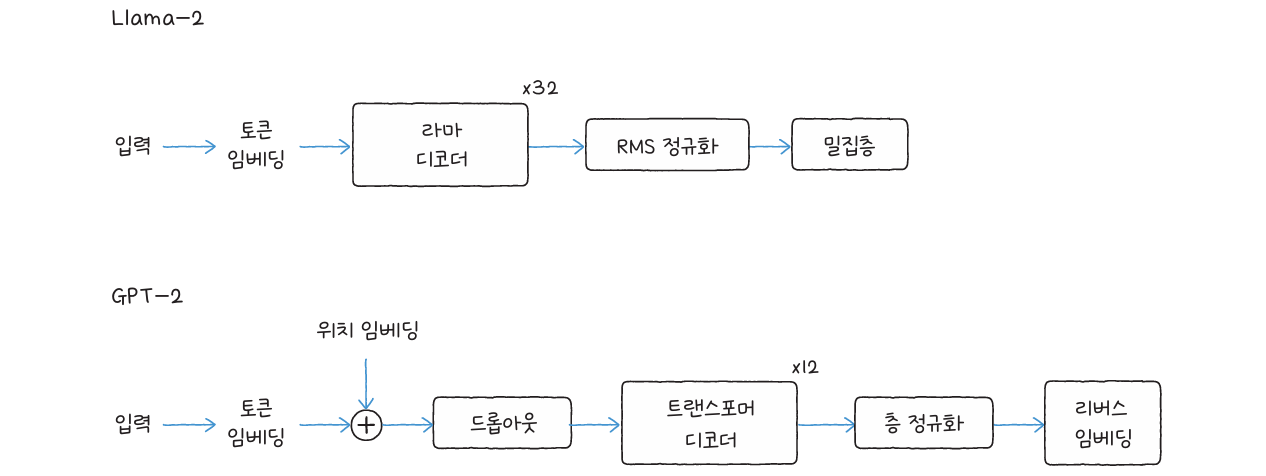
Llama는 메타에서 공개한 오픈소스 대규모 언어 모델로, 효율적인 훈련 방식과 높은 성능을 갖추고 있습니다. 로터리 위치 임베딩, RMS 정규화, SwiGLU 활성화 함수, 그룹 쿼리 어텐션 등 최신 기법들이 적용되어 성능과 효율을 동시에 개선했습니다.
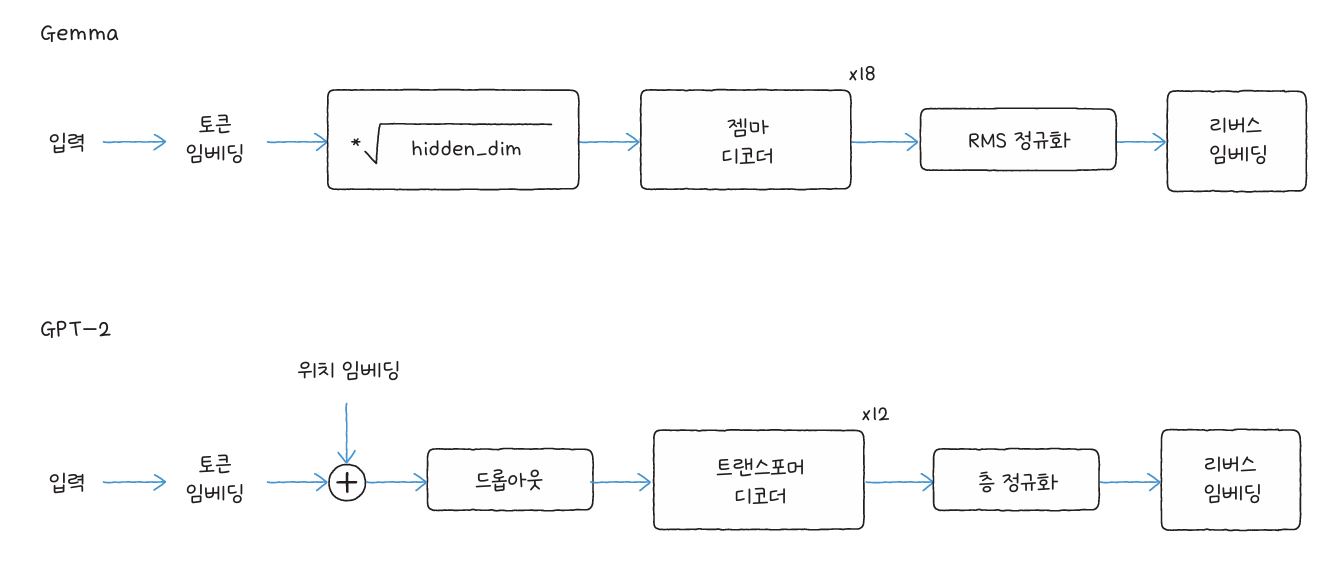
Gemma는 구글에서 공개한 트랜스포머 기반 모델로, 텍스트뿐 아니라 이미지와 오디오까지 처리할 수 있는 멀티모달 모델입니다. 소규모 모델부터 대규모 모델까지 다양한 버전을 제공하며, 케라스NLP와 허깅페이스를 통해 바로 활용 가능합니다.
이 세 가지 모델을 비교하며, 텍스트 생성 모델이 단순한 문장 예측을 넘어 맥락 기반 언어 생성으로 발전하고 있음을 확인할 수 있습니다.
✅ BART·T5 – 문장을 요약하거나 번역하는 인코더-디코더 모델
BART와 T5는 트랜스포머의 인코더와 디코더를 결합한 구조로, 입력된 텍스트를 분석하고 새로운 텍스트를 만들어 내는 모델입니다.

BART와 T5는 트랜스포머의 인코더와 디코더를 결합한 구조로, 입력된 텍스트를 분석하고 새로운 텍스트를 만들어 내는 모델입니다.
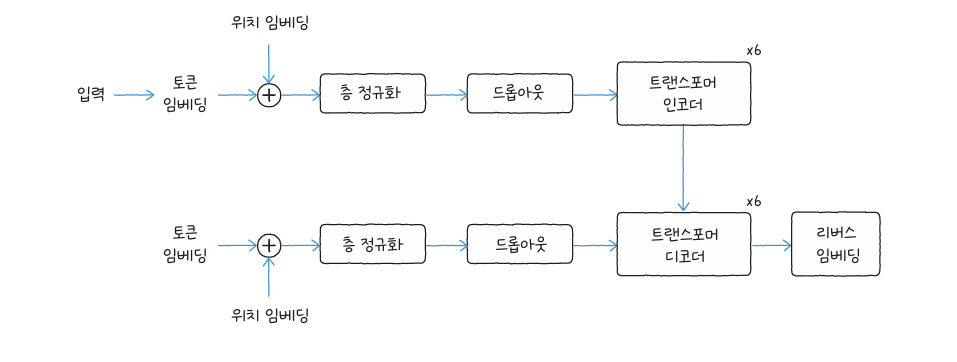
BART는 인코더가 입력 문장을 이해하고, 디코더가 요약문이나 변환 문장을 생성합니다. 디코더에는 인코더의 출력을 연결하기 위한 크로스 어텐션이 추가되어, 입력 문장에서 중요한 정보를 집중적으로 반영합니다. 허깅페이스의 facebook/bart-large-cnn 모델은 영문 뉴스 요약 작업에, 한국어 버전인 KoBART는 국문 요약이나 SNS 텍스트 요약에 자주 사용됩니다.
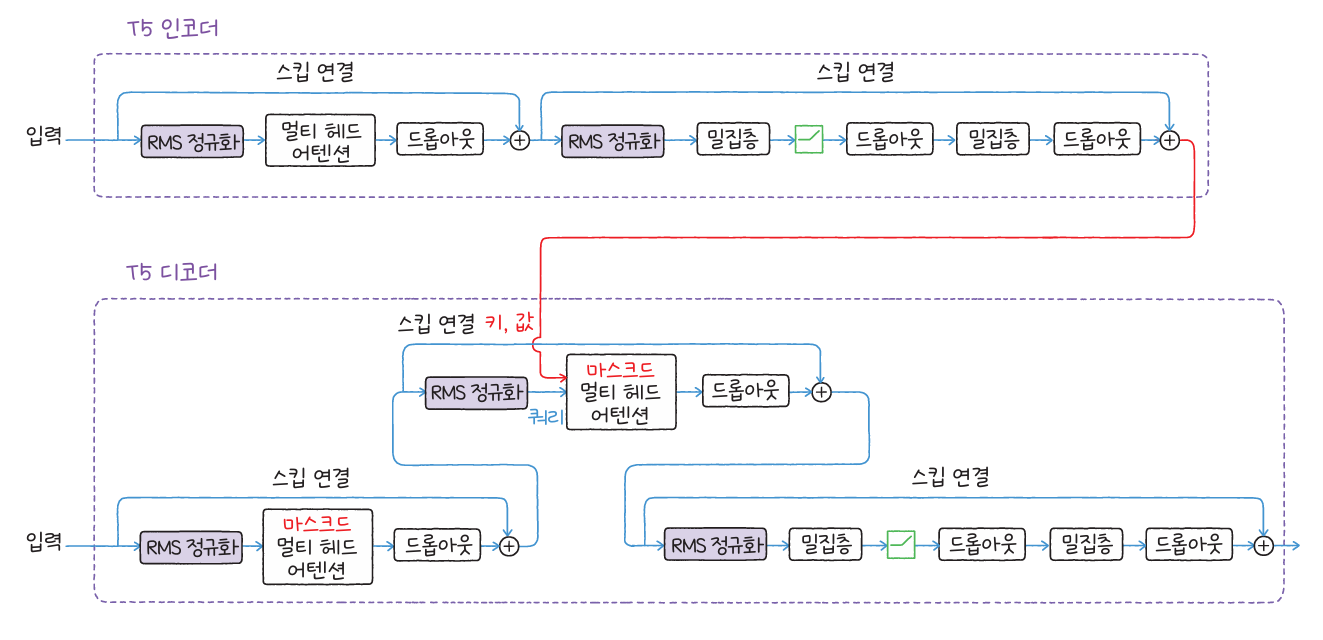
T5는 모든 자연어 처리 작업을 “텍스트 입력 → 텍스트 출력”이라는 하나의 형식으로 통합한 모델입니다. BART와 유사한 구조를 가지지만, 절대 위치 임베딩 대신 상대 위치 임베딩을 사용하여 문장 길이에 더 유연하게 대응합니다. 또한 T5-1.1 버전에서는 활성화 함수를 GeGLU로 변경하고, 피드 포워드 네트워크의 구조를 개선해 성능을 높였습니다.
케라스NLP의 T5MultiHeadAttention과 T5LayerNorm 클래스를 사용하면 T5를 직접 구현할 수 있으며, 허깅페이스에서 제공하는 사전 훈련 모델을 불러와 번역, 요약, 문장 재구성 등 다양한 작업을 실습할 수 있습니다.
LeNet-5에서 시작된 합성곱 신경망은 VGG, ResNet, EfficientNet을 거치며 점점 더 정교해졌고, 이후 트랜스포머 구조의 등장으로 BERT와 GPT 같은 언어 모델로 확장되었습니다. 딥러닝은 이제 이미지를 분류하고, 문장을 이해하며, 새로운 텍스트를 생성하는 수준까지 발전했습니다. 복잡한 이론보다 중요한 것은 모델이 어떤 문제를 해결하기 위해 설계되었는가를 이해하는 것입니다. 케라스와 허깅페이스 같은 도구를 통해 이러한 모델들을 직접 실행하고, 자신의 데이터에 적용해 보는 과정이 딥러닝 학습의 핵심입니다.
딥러닝은 어렵게 느껴질 수 있지만, 각 모델의 구조를 하나씩 따라가다 보면 데이터가 신경망을 통과하며 ‘이해’되는 과정을 명확히 볼 수 있습니다. LeNet에서 BERT, 그리고 GPT로 이어지는 흐름을 따라가며 인공지능이 데이터를 학습하고 스스로 패턴을 발견하는 방식을 직접 경험해 보세요.
 『혼자 공부하는 머신러닝+딥러닝』이 기본기를 다지는 데 집중했다면, 이 책은 딥러닝 분야에서 중요한 역할을 한 모델과 그 기술을 배우는 데 초점을 맞추었습니다.
『혼자 공부하는 머신러닝+딥러닝』이 기본기를 다지는 데 집중했다면, 이 책은 딥러닝 분야에서 중요한 역할을 한 모델과 그 기술을 배우는 데 초점을 맞추었습니다.
딥러닝 분야에서 대표적으로 활용되는 두 분야인 ✓컴퓨터 비전과 ✓대규모 언어 모델(LLM)을 중심으로, 초창기 CNN부터 GPT, Llama, Gemma 같은 최신 모델까지 따라 만들며 딥러닝의 핵심 기술 흐름을 자연스럽게 익힐 수 있습니다.
단순히 모델을 실행해보는 데서 끝나는 것이 아니라, 모델이 등장하고 발전해 온 과정을 함께 따라가며 새로운 기술에도 유연하게 대응할 수 있는 실력을 길러보세요.
• 동영상 강의: https://www.youtube.com/@HanbitMedia93
• 저자 블로그: https://tensorflow.blog

![[온라인] 바이브 코딩 AI 프로젝트 실전 특강(~2026.01.21)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/IT1팀_조태호의-바이브-코딩-AI-프로젝트-실전-특강_FB-1.png)
![[바이브 코딩] 클로드 코드 설치하기(Node.js, Git 설치 과정 포함)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/Installing-Claude-Code-Including-Node.js-and-Git-Installation.png)


Leave A Comment