요즘 인공지능을 공부해보려는 분들이 제일 먼저 만나는 건 GPT 같은 생성형 언어 모델일 겁니다. 질문만 잘 던져도 알아서 글을 써주고, 번역이나 요약, 코딩까지 해주는 모습을 보면 ‘이제는 그냥 프롬프트만 잘 쓰면 되는 시대 아닌가?’라는 생각이 들기도 하죠. 굳이 복잡한 알고리즘을 배우고, 수학 공부를 해야 하나 싶은 마음도 들고요.
GPT도 머신러닝에서 출발했습니다
하지만 실제로는, 겉보기에는 쉬워 보이는 기술일수록 그 구조를 제대로 이해하고 있는 사람이 훨씬 더 잘 활용할 수 있습니다. 특히 GPT나 Claude 같은 LLM(Large Language Model, 초거대 언어 모델)은 단순한 챗봇이 아니라, 여러 기술이 층층이 쌓여 만들어진 복합적인 모델입니다. 쉽게 말하면, ‘머신러닝 → 딥러닝 → 트랜스포머 → LLM’이라는 발전 흐름을 통해 등장한 결과물이라는 것이죠.
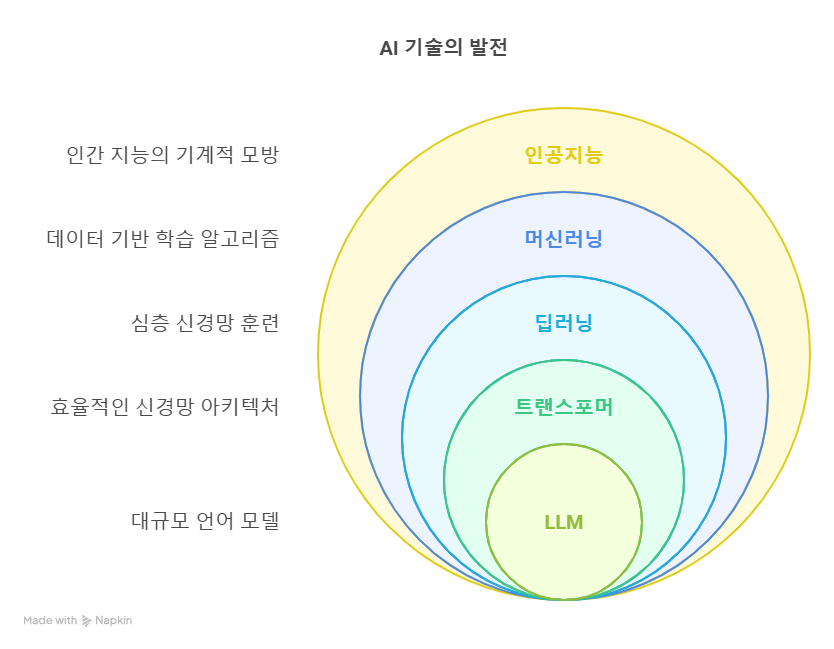
LLM을 ‘쓰는 사람’과 ‘이해하고 다루는 사람’의 차이
이 흐름을 이해하고 있으면, GPT를 단순히 ‘사용하는 사람’이 아니라, ‘제대로 활용하고 응용하는 사람’이 될 수 있습니다. 예를 들어, LLM이 가끔 말도 안 되는 얘기를 할 때가 있는데요. 이건 모델이 학습한 데이터에 과하게 의존하면서 잘못된 출력을 내는 현상으로, 머신러닝에서 말하는 ‘과적합’과 유사한 개념입니다. 이런 현상을 업계에서는 ‘할루시네이션(hallucination)’이라고 부르기도 하죠. 배경 개념을 알고 있다면, 왜 이런 문제가 생기는지 이해할 수 있고, 프롬프트를 바꾸거나 모델을 다르게 선택하는 식으로 보다 합리적인 대응이 가능해집니다.
GPT의 핵심: 어텐션 메커니즘과 트랜스포머 구조
또 GPT에서 핵심 역할을 하는 ‘어텐션 메커니즘’은, 입력 문장 안에서 어떤 단어에 더 집중할지를 결정하는 방식입니다. 이 구조는 트랜스포머 모델을 구성하는 핵심 기술이고, 기존의 순차 모델(RNN, LSTM 등)과는 다른 접근으로 빠르고 정교한 처리가 가능하게 만들었습니다. ,트랜스포머를 이해하면 GPT가 어떤 기준으로 문장을 이해하고, 어떤 방식으로 텍스트를 생성하는지를 자연스럽게 알 수 있게 됩니다.
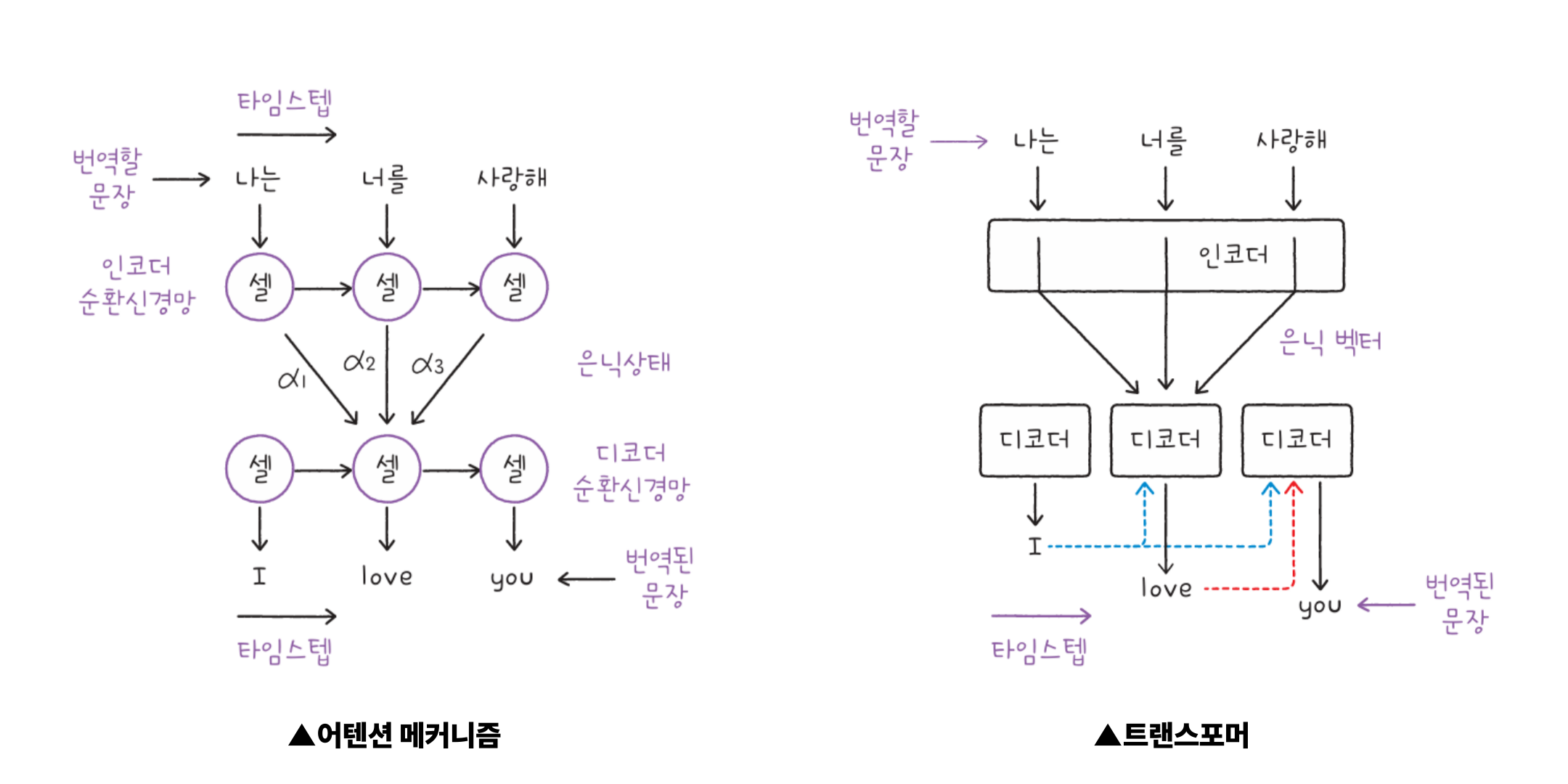
자연어 처리 기술의 흐름 안에 있는 LLM
자연어 처리(NLP)라는 관점에서도 LLM은 그 흐름 속에 있는 기술입니다. 모델은 방대한 양의 텍스트 데이터를 학습하여 문맥에 따라 다음 단어를 예측합니다. 이처럼 단어의 순서를 고려한 처리는 ‘순차 데이터’를 다루는 기술을 기반으로 하며, GPT 이전에도 다양한 모델(RNN, LSTM, GRU 등)이 존재했습니다. 트랜스포머는 이러한 기존 기술의 한계를 보완하며 등장했고, LLM은 그 트랜스포머 구조 위에 구축된 기술이라고 볼 수 있습니다.
결국 LLM도 머신러닝 기초 위에 서 있습니다
결국 LLM은 복잡한 기술이지만, 그 핵심은 우리가 흔히 말하는 머신러닝과 딥러닝의 기초 개념에 기반해 있습니다. 예측 모델이 어떻게 학습되고, 데이터를 어떻게 나눠서 검증하고, 모델의 성능을 어떤 기준으로 판단하고 개선할 수 있는지 이런 기초적인 원리를 알고 있으면, LLM도 훨씬 더 잘 이해할 수 있고, 보다 주도적으로 다룰 수 있습니다.
요즘처럼 새로운 기술이 빠르게 등장하는 시대에는 ‘기초를 건너뛰고 빨리 써보고 싶다’는 마음이 들게 됩니다. 하지만 결국, 기술을 깊이 있게 이해하고 응용하려면 기초 개념을 알아야 합니다. LLM은 분명 강력한 도구지만, 그 도구를 더 잘 다루기 위해서는 그 밑바탕에 있는 머신러닝과 딥러닝의 기본 개념을 함께 공부해두는 것이 분명 도움이 될 것입니다.
 이번 개정판에서는 트랜스포머와 대규모 언어 모델(LLM) 실습을 새롭게 추가하고, 독자 요청이 많았던 파이토치 예제 코드를 보강해 케라스와 파이토치까지 익힐 수 있도록 학습의 폭을 넓혔습니다. 인공지능 분야는 점점 더 빠르게 발전하고 있습니다. 공부를 미루지 마세요. 이 책을 펼친 지금이 바로 공부하기 좋은 최적의 순간입니다! (۶•̀ᴗ•́)۶
이번 개정판에서는 트랜스포머와 대규모 언어 모델(LLM) 실습을 새롭게 추가하고, 독자 요청이 많았던 파이토치 예제 코드를 보강해 케라스와 파이토치까지 익힐 수 있도록 학습의 폭을 넓혔습니다. 인공지능 분야는 점점 더 빠르게 발전하고 있습니다. 공부를 미루지 마세요. 이 책을 펼친 지금이 바로 공부하기 좋은 최적의 순간입니다! (۶•̀ᴗ•́)۶

![[온라인] 바이브 코딩 AI 프로젝트 실전 특강(~2026.01.21)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/IT1팀_조태호의-바이브-코딩-AI-프로젝트-실전-특강_FB-1.png)
![[바이브 코딩] 클로드 코드 설치하기(Node.js, Git 설치 과정 포함)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/Installing-Claude-Code-Including-Node.js-and-Git-Installation.png)


Leave A Comment