
✍두 줄 요약: ‘인공지능 > 머신러닝 > 딥러닝 순서로 범위가 크다’ 라고 이해하시면 편합니다.
인공지능은 머신러닝과 딥러닝을 포괄하는 개념!
인공지능, 머신러닝, 딥러닝! 많이 들어봤지만 정확하게 개념이 잡혀있지 않은 분들을 위해 각각 무엇인지 알아보고 그 차이를 간단하게 정리해보겠습니다.
인공지능이 무엇이라고 설명하지 않아도 무엇인지 감이 오실 거예요.
우리가 사는 세상에는 이미 인공지능이 다양하게 생활 속 깊숙이 들어와 있거든요.
몇 가지 생활 속의 인공지능을 소개해 드리겠습니다.
이미 알고 있거나, 친숙한 서비스와 브랜드가 있을 거예요.
🧠생활 속 인공지능은 무엇이 있을까?
- 자율 주행 자동차: 테슬라, 구글, 현대자동차&네이버
- 스마트 스피커(AI 비서): 아마존, 구글, 바이두, 알리바바, 샤오미, KT, SK 텔레콤, 네이버, 카카오, 삼성전자 등
- 챗봇: 카카오 상담톡, 네이버 톡톡, 라인, 채널톡 등
- 인공지능 로봇: 청소 로봇, 교육용 로봇, 동반자 로봇, 운송 로봇
- 이미지 인식: 페이스북, 구글, 마이크로소프트, 네이버
- 개인화 추천: 넷플릭스,구글, 페이스북
- 기계 번역: 구글, 네이버 파파고
🧠간단히 살펴보는 인공지능의 역사
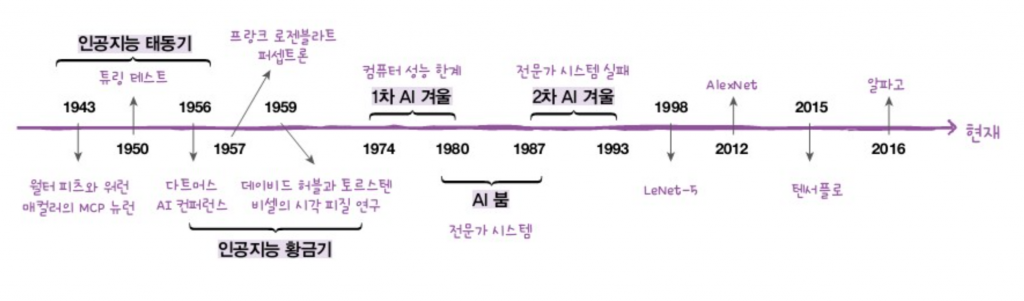
무려 2번의 힘든 시기(AI 겨울이라고 불러요.)를 보낸 인공지능 분야는 알파고가 등장하기 전까지는 소설이나 영화 속의 단골 소재로 쓰였어요. 스티븐 스필버그 감독의 <A.I.>라든가, 호아킨 피닉스가 열연한 <her>를 보거나 들어보셨을 거예요.

하지만 알파고가 등장한 이후, 인공지능은 좀 더 우리와 가까워진 현실 속의 기술로 발전하고 있습니다. 알파고가 등장한 게 2016년 3월이니 불과 5년 만에 우리 생활 속에 인공지능, 머신러닝, 딥러닝이라는 단어가 깊숙이 파고들었다고 할 수 있어요.
기나긴 인공지능의 역사를 여기에서 모두 나열하지는 않을 거예요. 오늘은 중요 사건을 요약한 그림을 보면서 인공지능, 머신러닝, 딥러닝이 무엇인지 알아보겠습니다.
🤖인공지능이란?
인공지능artificial intelligence은 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술입니다. 인공지능의 역사는 약 80년 남짓 되었지만 인류는 훨씬 더 오래전부터 지능적인 시스템을 생각했습니다. 지능을 가진 로봇을 다룬 최초의 소설은 150년 전으로 거슬러 올라갑니다.
1943년 워런 매 컬러Warren McCulloch와 월터 피츠Walter Pitts는 최초로 뇌의 뉴런 개념을 발표했습니다. 1950년에는 앨런 튜링 Alan Turing이 인공지능이 사람과 같은 지능을 가졌는지 테스트할 수 있는 유명한 튜링 테스트 Turing Test를 발표합니다. 많은 과학자가 참여한 1956년 다트머스 AI 콘퍼런스Dartmouth AI Conference에서는 인공지능에 대한 장밋빛 전망이 최고조에 도달했습니다.
이 시기를 인공지능 태동기👶라고 합니다.
그 이후 인공지능 황금기✨가 도래했습니다. 대표적으로 1957년 프랑크 로젠블라트Frank Rosenblatt가 로지스틱 회귀의 초기 버전으로 볼 수 있는 퍼셉트론Perceptron을 발표했습니다. 1959년에는 데이비드 허블David Hubel과 토르스텐 비셀Torsten Wiesel이 고양이를 사용해 시각 피질에 있는 뉴런 기능을 연구했습니다. 나중에 두 사람은 그 공로를 인정받아 노벨상을 수상했습니다.
하지만 컴퓨터 성능의 한계로 인해 간단한 문제를 해결하는 것에 그치자 ❄첫 번째 AI 겨울❄이 도래했습니다. 이 기간에는 인공지능에 대한 연구와 투자가 크게 감소했습니다. 그다음 전문가 시스템expert system이 등장했고 두 번째 AI 붐이 불었지만, 역시 또 한계를 드러내고 ❄두 번째 AI 겨울❄을 맞이합니다.
이 시기를 극복한 후에 인공지능은 다시 각광을 받기 시작했고 연구자들은 물론 대중 매체도 어느 때 보다 큰 관심을 가지게 되었습니다. 이제는 영화와 드라마, 소설 속에서 지능을 가진 컴퓨터 시스템이 등장하는 것이 흔합니다. 하지만 영화 속에 등장하는 인공지능을 실생활에서 체험하기는 아직 어렵습니다. 스마트폰의 음성 비서와 간단한 대화를 이어가기도 아직은 어렵습니다. 영화와 현실이 차이 나는 것은 두 기술이 다르기 때문입니다.
👱♀️사만다와 🤖스카이넷

흔히 영화 속의 인공지능은 인공일반지능artificial general intelligence 혹은 강인공지능Strong AI이라고 부르는 인공지능입니다. 영화 <her>에 나온 인공지능 사만다를 기억하나요? 사만다의 진짜 이름은 OS1으로 이어서 설명할 강인공지능의 한 예입니다. 사만다나 지금도 가장 사악한 인공지능으로 불리는 <터미네이터>의 스카이넷처럼 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템이 인공일반지능입니다.
반면 현실에서 우리가 마주하고 있는 인공지능은 약인공지능Weak AI입니다. 약인공지능은 아직까지는 특정 분야에서 사람의 일을 도와주는 보조 역할만 가능합니다. 예를 들면 음성 비서, 자율 주행 자동차, 음악 추천, 기계 번역 등입니다. 또 이세돌과 바둑 시합을 한 알파고가 좋은 예입니다.
그럼 언제 강인공지능에 도달할 수 있을까요? 아직은 아무도 그 시기를 정확히 알 수 없지만 가능성에 대해서는 대체로 긍정적입니다. 그렇지만 가까운 미래에 이런 기술이 도래하리라 낙관하지는 않았으면 좋겠습니다. 여기에는 거품이 끼어 있을 수 있습니다. 앞서 언급했듯이 과거에도 이 분야에서는 성급하게 장밋빛 청사진을 제시하다가 실패한 경우가 있기 때문입니다.
🤖머신러닝이란?
머신러닝machine learning은 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야입니다.
머신러닝은 통계학과 깊은 관련이 있습니다. 통계학에서 유래된 머신러닝 알고리즘이 많으며 통계학과 컴퓨터 과학 분야가 상호 작용하면서 발전하고 있습니다. 대표적인 오픈소스 통계 소프트웨어인 R에는 다양한 머신러닝 알고리즘이 구현되어 있습니다.
하지만 최근 머신러닝의 발전은 통계나 수학 이론보다 경험을 바탕으로 발전하는 경우도 많습니다. 컴퓨터 과학 분야가 이런 발전을 주도하고 있습니다. 컴퓨터 과학 분야의 대표적인 머신러닝 라이브러리는 사이킷런scikit-learn입니다.

사이킷런 라이브러리는 파이썬 API를 사용하는데 파이썬 언어는 배우기 쉽고 컴파일하지 않아도 되기 때문에 사용하기 편리합니다. 머신러닝 분야에 관심이 높아지면서 파이썬과 함께 사이킷런 라이브러리가 큰 인기를 얻고 있습니다. 이제는 사이킷런 외에 대표적인 다른 머신러닝 라이브러리를 찾아보기 힘듭니다. 파이썬으로 print(‘Hello world’) 명령을 출력할 수 있다면 누구나 조금만 배워 머신러닝 프로그램을 만들 수 있습니다. 사이킷런 라이브러리에서 제공하는 클래스와 함수를 사용하여 필요한 작업을 수행할 수 있습니다.
당연하지만 사이킷런에 모든 머신러닝 알고리즘이 포함되어 있지는 않습니다. 연구자들은 새로운 알고리즘을 끊임없이 개발하여 발표합니다. 많은 사람이 이를 검증하고 사용해 본 다음 장단점을 파악하게 됩니다. 어느 정도 시간이 지나서 이런 알고리즘이 유익하다고 증명되어 널리 사용하게 되면 사이킷런 라이브러리 개발자들이 이 알고리즘을 라이브러리에 추가합니다. 그러므로 머신러닝 라이브러리에 포함된 알고리즘들은 안정적이며 성능이 검증되어 있습니다. 비교적 안심하고 사용할 수 있는 이유입니다.
프로그래머가 직접 알고리즘을 구현하느라 힘들게 프로그램을 짤 필요가 없습니다. 어떻게 머신러닝 알고리즘을 선택하고 활용할 수 있는지를 먼저 생각해보는 것도 방법이 될 수 있는 것입니다.
사이킷런이 있기 전까지 머신러닝 기술은 대부분 폐쇄적인 코드와 라이브러리로 통용되었습니다. 해당 분야에 대해 전문 교육을 이수하거나 비싼 비용을 지불하고 구매를 해야 했습니다. 하지만 사이킷런과 같은 오픈소스 라이브러리의 발전 덕분에 머신러닝 분야는 말 그대로 폭발적으로 성장했습니다. 파이썬 코드를 다룰 수 있다면 누구나 머신러닝 알고리즘을 무료로 손쉽게 제품에 활용할 수 있습니다. 덕분에 현대의 개발자는 머신러닝 알고리즘을 이해하고 사용할 수 있어야 합니다.
이런 현상으로 인해 새로운 이론과 기술은 직접 코드로 구현되고 통용되어야 그 가치를 입증할 수 있게 되었습니다. 코드로 구현되어 성능을 입증하지 못하면 탁상공론에 지나지 않고 사람들의 주목을 끌기 어렵습니다. 이런 기조는 딥러닝 분야에서 더욱 증폭되었습니다.
🤖딥러닝이란?
많은 머신러닝 알고리즘 중에 인공 신경망artificial neural network을 기반으로 한 방법들을 통칭하여 딥러닝 deep learning이라고 부릅니다. 종종 사람들은 인공 신경망과 딥러닝을 크게 구분하지 않고 사용합니다.
❄두 번째 AI 겨울❄ 기간에도 여전히 인공지능에 대해 연구한 사람들이 있었습니다. 이들의 연구가 차츰 빛을 보면서 다시 인공지능 기술이 주목받기 시작했습니다. 1998년 얀 르쿤Yann Lecun이 신경망 모델을 만들어 손글씨 숫자를 인식하는 데 성공했습니다. 이 신경망의 이름을 LeNet-5라고 하며 최초의 합성곱 신경망입니다.
그 이후 2012년에 제프리 힌턴Geoffrey Hinton의 팀이 이미지 분류 대회인 ImageNet에서 기존의 머신러닝 방법을 누르고 압도적인 성능으로 우승했습니다. 힌턴이 사용한 모델의 이름은 AlexNet이며 역시 합성곱 신경망을 사용했습니다. 이때부터 이미지 분류 작업에 합성곱 신경망이 널리 사용되기 시작했습니다.


국내에서는 2016년 이세돌과 알파고의 대국으로 인해 딥러닝에 대한 관심이 크게 높아졌습니다. 하지만 앞에서 소개했듯이 딥러닝은 2010년 초반부터 이렇게 새로운 혁명을 준비하고 있었습니다. LeNet-5나 AlexNet과 같이 인공 신경망이 이전과 다르게 놀라운 성능을 달성하게 된 원동력으로 크게 세 가지를 꼽을 수 있습니다.

복잡한 알고리즘을 훈련할 수 있는 풍부한 데이터와 컴퓨터 성능의 향상, 그리고 혁신적인 알고리즘 개발입니다. 인공지능에 대한 과거의 시도와 달리 최근의 딥러닝 발전은 매우 긍정적이고 지속 가능해 보입니다. 이런 오픈소스 머신러닝 라이브러리의 영향력을 눈치챘던 것일까요. 2015년 구글은 딥러닝 라이브러리인 텐서플로TensorFlow를 오픈소스로 공개했습니다. 텐서플로는 공개와 동시에 큰 인기를 얻었으며 아직까지 가장 널리 사용되는 딥러닝 라이브러리입니다. 페이스북도 2018년 파이토치PyTorch 딥러닝 라이브러리를 오픈소스로 공개했습니다.
이 라이브러리들의 공통점은 인공 신경망 알고리즘을 전문으로 다루고 있다는 것과 모두 사용하기 쉬운 파이썬 API를 제공한다는 점입니다.
🙋♂️인공지능, 머신러닝, 딥러닝의 차이점은 무엇입니까?
👨🏫 범위에 차이가 있습니다. 인공지능이 범위가 가장 크고, 머신러닝이 중간이며, 딥러닝이 가장 작습니다.
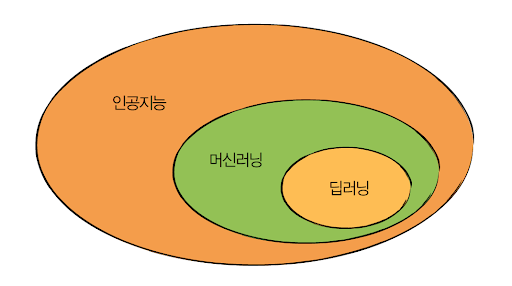
△그림 1-1 인공지능 > 머신러닝 > 딥러닝
지금까지 인공지능, 머신러닝, 딥러닝에 대하여 간단하게 알아보았습니다. 그럼 인공지능과 인공신경망은 어떻게 다른 것일까요? 머신러닝과 딥러닝은요?
인공지능은 컴퓨터가 인간의 사고를 모방하는 모든 것을 뜻한다고 보고 있습니다. 그리고 머신러닝machine learning은 컴퓨터가 스스로 학습하는 것을 말합니다. 특히 주어진 데이터를 이용해서 말이죠. 마지막으로 딥러닝deep learning으로 대표되는 인공신경망artificial neural network은 머신러닝을 구현하는 기술의 하나로, 인간 뇌의 동작 방식에서 착안하여 개발한 학습 방법이라고 할 수 있겠습니다. 그래서 인공지능이 범위가 가장 크고, 머신러닝이 중간이며, 딥러닝이 가장 작습니다.
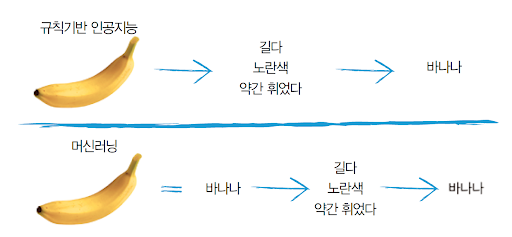
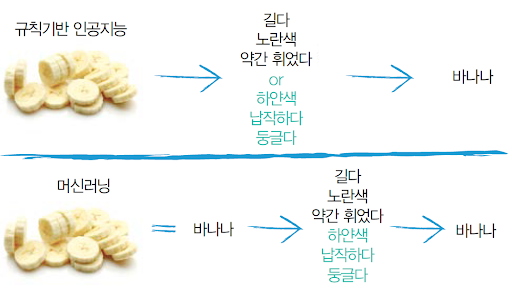
△그림 1-2 규칙기반과 머신러닝 기반의 바나나 인식
이 3가지 용어의 차이점을 설명하기 위해서 간단하게 예를 들어보겠습니다. [그림 1-2]의 위쪽처럼 기존의 인공지능인 규칙기반 인공지능rule-based AI이 바나나를 인식하도록 하려면 인간이 컴퓨터에 바나나를 식별하는 특징feature을 가르쳐줘야 했습니다. “길고, 노란색이고, 약간 휜 물체면 바나나야”라는 식이죠.
하지만 머신러닝의 학습 방식은 [그림 1-2]의 아래쪽과 같습니다. 바나나 사진을 주고 “이것이 바나나야”라고 하면 컴퓨터가 스스로 바나나의 특징을 학습합니다. “음. 바나나는 길고, 노란색이고, 휜 것이군”이라고 말이죠.
| 🙋♀️여기서 잠깐) 머신러닝에는 다양한 방법이 있지만, 간략히 설명하기 위해 약간 비약하였습니다. 참고로 이러한 방법을 end-to-end 학습이라고 하며, 딥러닝이 바로 이러한 방식으로 학습합니다 |
그러면 인공지능에 썰어놓은 바나나를 추가로 인식시키려면 어떻게 해야 할까요? 규칙기반 인공지능은 앞의 규칙에 “하얀색이고, 납작하고, 둥글다”라는 특징을 수작업으로 추가해줘야 합니다. 하지만 머신러닝은 썰어놓은 바나나 사진만 입력해주면 알아서 새로운 특징을 학습하고 인식할 수 있습니다.
△그림 1-3 썰어놓은 바나나를 인식하는 방법
즉, 풀고자 하는 문제가 복잡할수록 규칙기반 인공지능보다는 머신러닝을 이용한 인공지능이 문제를 훨씬 더 효율적으로 해결할 수 있으리라 예상할 수 있습니다. 인간이 모든 특징을 분석하고 알고리즘을 만들어서 입력하는 것보다, 컴퓨터가 직접 특징을 추출하는 쪽이 더 빠르고 정확하다면 말이죠.
🙋♂️지금 인공지능, 머신러닝, 딥러닝을 배워도 되나요?
👨🏫 지금이 인공지능을 배우기 가장 좋은 때라고 생각합니다.
컴퓨터 과학은 추상화의 학문이라고 해도 과언이 아닙니다. 더군다나 요즘엔 좀처럼 실제 컴퓨터를 조립할 기회도 많지 않습니다. 예전에 다양한 주변 장치가 담당했던 일을 하나의 칩이 대신합니다. 스마트폰은 이런 경향의 절정에 있습니다. 그러다 보니 피부로 느끼는 추상화는 더욱더 심하죠. 이런 추상화의 단점은 개념을 모호하게 만들고 외부에서 접근하기 어렵게 만든다는 점입니다. 눈에 보이지 않는 소프트웨어만으로 개념을 이해하고 알고리즘을 풀어내야 하는 일이 처음 배우는 사람에게 특히 어렵습니다.
아마 데이터 마이닝data mining, 빅데이터big data, 데이터 과학data science 와 같은 용어를 들어 보셨을지도 모릅니다. 이런 용어는 기술적을 설명하는 마케팅에 가깝습니다. 용어 차이를 명확히 구분하기 힘들고 그 안에 속한 기술을 정확히 정의하기도 어렵습니다.
사실 이런 기술은 모두 인공지능의 큰 범주 안에 포함됩니다. 시대와 트렌드에 따라 옷을 바꿔 입었지만 큰 흐름은 모두 일맥상통하죠. 그리고 이제 이런 기술이 머신러닝과 딥러닝에 이르러 절정을 이루고 있습니다. 3번째 전성기를 맞은 지금이 이 기술을 배우기 가장 좋은 때라는 것은 의심의 여지가 없습니다.
🔑 꼭 알아두면 좋은 키워드 정리!
- 인공지능(Artificial intelligence): 인공지능은 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술입니다. 인공지능은 강인공지능과 약인공지능으로 나눌 수 있습니다.
- 머신러닝(Machine Learning): 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야입니다. 사이킷런이 대표적인 라이브러리입니다.
- 사이킷런(scikit-learn): 2007년 구글 썸머 코드에서 처음 구현되었으며, 가장 널리 사용되는 머신러닝 패키지 중 하나입니다.
- 인공 신경망(Artificial Neural Network): 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘입니다. 신경망은 기존의 머신러닝 알고리즘으로 다루기 어려웠던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목 받고 있으며 종종 딥러닝이라고도 부릅니다.
- 딥러닝(Deap learnging): 딥러닝은 인공 신경망이라고도 하며, 텐서플로와 파이토치가 대표적인 라이브러리입니다.
- 텐서플로(TensorFlow): 구글이 만든 딥러닝 라이브러리로 CPU와 GPU를 사용해 인공신경망 모델을 효율적으로 훈련하며 모델 구축과 서비스에 필요한 다양한 도구를 제공합니다.텐서플로 2.0부터는 신경망 모델을 빠르게 구성할 수 있는 케라스Keras를 핵심 API로 채택하였습니다. 케라스를 사용하면 간단한 모델에서 아주 복잡한 모델까지 비교적 손쉽게 만들 수 있습니다.
- 파이토치(Pytorch): Facebook에서 개발하여 2016년 공개한 파이썬 기반의 오픈소스 머신러닝 라이브러리를 말합니다.
- 케라스(Keras): 다양한 인공지능 엔진에서 지원하며, 2015년에 공개된 파이썬 기반의 오픈소스 신경망 라이브러리입니다. 텐서플로, 파이토치와 함께 널리 사용되고 있습니다.
👥이 글에서 소개한 두 명의 딥러닝 구루
👨제프리 힌턴: 1947년 태어난 제프리 힌턴은 인공지능 분야를 개척한 영국 출신의 인지심리학자이자 컴퓨터 과학자입니다. 1978년 에딘버러에서 AI 박사 학위를 받았습니다. 현재 캐나다 토론토 대학교의 교수이며, 구글(VP Engineering fellow)에서 겸직하고 있습니다.
👨얀 르쿤: 1960년 태어난 얀 르쿤은 프랑스계 미국인으로 기계학습, 컴퓨터비전, 모바일 로보틱스 그리고 신경망을 연구하고 있습니다. 현재 페이스북 AI를 이끌고 있습니다.
위 내용은 <혼자 공부하는 머신러닝+딥러닝>과 <골빈해커의 3분 딥러닝>을 재구성하여 작성 되었습니다.

이 책을 통해 인공지능의 추상화를 걷어내고 직접 코딩하면서 머신러닝과 딥러닝의 실체가 무엇인지 배워 보세요.
모든 예제는 공개 되어 있으며, 온라인 환경인 구글 코랩에서 실습합니다. 회귀 알고리즘부터 시작해 텐서플로를 사용한 딥러닝 알고리즘을 다룹니다.
기본적인 인공 신경망에서부터 이미지 처리 분야에 뛰어난 합성곱 신경망과 순차 데이터 처리에 뛰어난 순환 신경망까지 원리를 터득하고 직접 모델을 구현하여 예제를 풀어 보실 수 있습니다.

![[온라인] 바이브 코딩 AI 프로젝트 실전 특강(~2026.01.21)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/IT1팀_조태호의-바이브-코딩-AI-프로젝트-실전-특강_FB-1.png)
![[바이브 코딩] 클로드 코드 설치하기(Node.js, Git 설치 과정 포함)](https://hongong.hanbit.co.kr/wp-content/uploads/2026/01/Installing-Claude-Code-Including-Node.js-and-Git-Installation.png)


좋은 글. 깔끔한 정리 고맙습니다. 감사합니다.
잘 보고 갑니다.
잘 정리해주셔서 고맙습니다. 덕분에 많이 배웠습니다.
정말 잘 정리된 글이네요.
감사합니다! 항상 헷갈리던 개념들이었는데 너무 잘 정리해주셨네요!
한시간 동안 ai 관련 직업들과 단어들 계속 찾았는데 저마다 해석이 다 다르고, 용어도 너무 어려운 전문용어에 추상적으로 설명하는 글들이 산더미였는데 이 글은 너무나 이해가 쉽고 잘 정리되어있다. 이런 글이 흥해야함